
首页 > 安防资讯网 谷歌发布RT-2,实体机器人版ChatGPT来了!
谷歌发布RT-2,实体机器人版ChatGPT来了!
智东西7月29日消息,Google DeepMind再放AI机器人大招!周五,这家前沿AI研究机构宣布以训练AI聊天机器人的方式训练了一款全新的机器人模型Robotic Transformer 2(RT-2)。
RT-2相当于机器人版ChatGPT,被Google DeepMind称作是其视觉-语言-动作 (VLA)模型的新版本。该模型可以教会机器人更好地识别视觉和语言模态,能够解释人类用自然语言发出的指令,并推断出如何做出相应的行动。它还可以理解英语以外的语言的指示。
结合思维链推理,RT-2可以执行多阶段语义推理。即便是一些抽象概念,RT-2也能理解并指挥机械臂做出正确的动作。比如让它找一把临时用的简易锤子,它会抓起石头;让它给疲惫的人选一款饮料,它会选择红牛;让它把可乐罐移到泰勒·斯威夫特的照片上,它也能顺利完成。
根据论文,RT-2模型基于网络和机器人数据进行训练,利用了谷歌自己的Bard等大型语言模型的研究进展,并将其与机器人数据(例如要移动的关节)相结合,然后将这些知识转化为机器人控制的通用指令,同时保留web-scale能力。
论文地址:
https://robotics-transformer2.github.io/assets/rt2.pdf
Google DeepMind博客文章写道,RT-2显示出超越其所接触的机器人数据的泛化能力以及语义和视觉理解能力,包括解释新命令并通过执行基本推理(例如关于对象类别或高级描述的推理)来响应用户命令。
其将信息转化为行动的能力表明,机器人有望更快地适应新的情况和环境。
在对RT-2模型进行了超过6000次的机器人试验后,研究团队发现,RT-2在训练数据或“可见”任务上的表现与之前的模型RT-1一样好。它在新奇的、不可预见的场景中的表现几乎翻番,从RT-1的32%提高到62%。
01. 让机器人用AI大模型学习新技能
机器人技术领域正悄然进行一场革命——将大型语言模型的最新进展引入机器人,让机器人变得更聪明,并具备新的理解和解决问题的能力。
《纽约时报》技术专栏作家凯文·罗斯(Kevin Roose)在谷歌机器人部门观看了实际演示,工程师给机器人发出指令:“捡起灭绝的动物”,一个单臂机器人呼呼地响了一会儿,然后伸出机械臂,爪子张开落下,准确抓住了它面前桌子上的恐龙塑料制品。
在这场长达1小时的演示中,RT-2还成功执行了“将大众汽车移到德国国旗上”的复杂指令,RT-2找到并抓住一辆大众巴士模型,并将其放在几英尺外的微型德国国旗上。

▲两名谷歌工程师Ryan Julian(左)和Quan Vuong成功指示RT-2“将大众汽车移到德国国旗上”。(图源:《纽约时报》)
多年以来,谷歌和其他公司的工程师训练机器人执行机械任务(例如翻转汉堡)的方式是使用特定的指令列表对其进行编程。然后机器人会一次又一次地练习该任务,工程师每次都会调整指令,直到得到满意的结果为止。
这种方法适用于某些有限的用途。但以这种方式训练机器人,既缓慢又费力。它需要从现实世界的测试中收集大量数据。如果你想教机器人做一些新的事情(例如从翻转汉堡改做翻转煎饼),你通常必须从头开始重新编程。
部分源于这些限制,硬件机器人的改进速度慢于基于软件的同类机器人。
近年来,谷歌的研究人员有了一个想法:如果机器人使用AI大型语言模型(来为自己学习新技能,而不是逐一为特定任务进行编程,会怎样?
据谷歌研究科学家卡罗尔·豪斯曼(Karol Hausman)介绍,他们大约两年前开始研究这些语言模型,意识到它们蕴藏着丰富的知识,所以开始将它们连接到机器人。
高容量视觉-语言模型(VLM)在web-scale数据集上进行训练,使这些系统非常擅长识别视觉或语言模式并跨不同语言进行操作。但要让机器人达到类似的能力水平,他们需要收集每个物体、环境、任务和情况的第一手机器人数据。
RT-2的工作建立在RT-1的基础上。这是一个经过多任务演示训练的模型,可学习机器人数据中看到的任务和对象的组合。更具体地说,谷歌的研究工作使用了在办公室厨房环境中用13个机器人在17 个月内收集的RT-1机器人演示数据。
谷歌首次尝试将语言模型和物理机器人结合起来是一个名为PaLM-SayCan的研究项目,该项目于去年公布,它引起了一些关注,但其用处有限。机器人缺乏解读图像的能力,而这是能够理解世界的一项重要技能。他们可以为不同的任务写出分步说明,但无法将这些步骤转化为行动。
谷歌的新机器人模型RT-2就能做到这一点。这个“视觉-语言-动作”模型不仅能够看到和分析周围的世界,还能告诉机器人如何移动。
它通过将机器人的动作转换为一系列数字(这一过程称为标注)并将这些标注合并到与语言模型相同的训练数据中来实现这一点。
最终,就像ChatGPT或Bard学会推测一首诗或一篇历史文章中接下来应该出现什么词一样,RT-2可以学会猜测机械臂应该如何移动来捡起球,或将空汽水罐扔进回收站垃圾桶。
02. 采用视觉语言模型进行机器人控制
RT-2表明视觉-语言模型(VLM)可以转化为强大的视觉-语言-动作(VLA)模型,通过将VLM预训练与机器人数据相结合,直接控制机器人。
RT-2以视觉-语言模型(VLM)为基础,将一个或多个图像作为输入,并生成一系列通常代表自然语言文本的标注。此类VLM已接受web-scale数据的训练,能够执行视觉问答、图像字幕或对象识别等任务。Google DeepMind团队采用PaLI-X和PaLM-E模型作为RT-2的支柱。
为了控制机器人,必须训练它输出动作。研究人员通过将操作表示为模型输出中的标注(类似于语言标注)来解决这一挑战,并将操作描述为可以由标准自然语言标注生成器处理的字符串,如下所示:
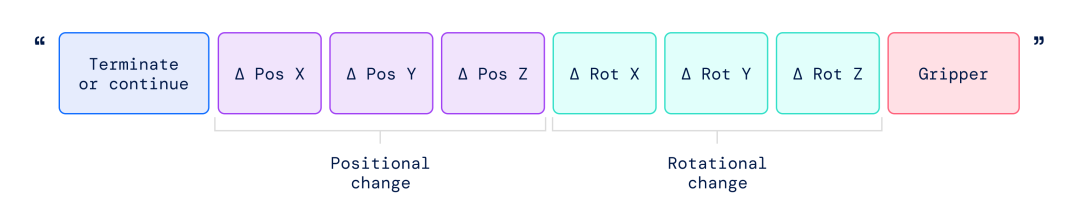
▲RT-2训练中使用的动作字符串的表示形式。这种字符串的示例可以是机器人动作标记编号的序列,例如“1 128 91 241 5 101 127 217”。
该字符串以一个标志开头,指示是继续还是终止当前情节,而不执行后续命令,然后是更改末端执行器的位置和旋转以及机器人夹具所需延伸的命令。
研究人员使用了与RT-1中相同的机器人动作离散版本,并表明将其转换为字符串表示使得可以在机器人数据上训练VLM模型,因为此类模型的输入和输出空间不需要改变了。
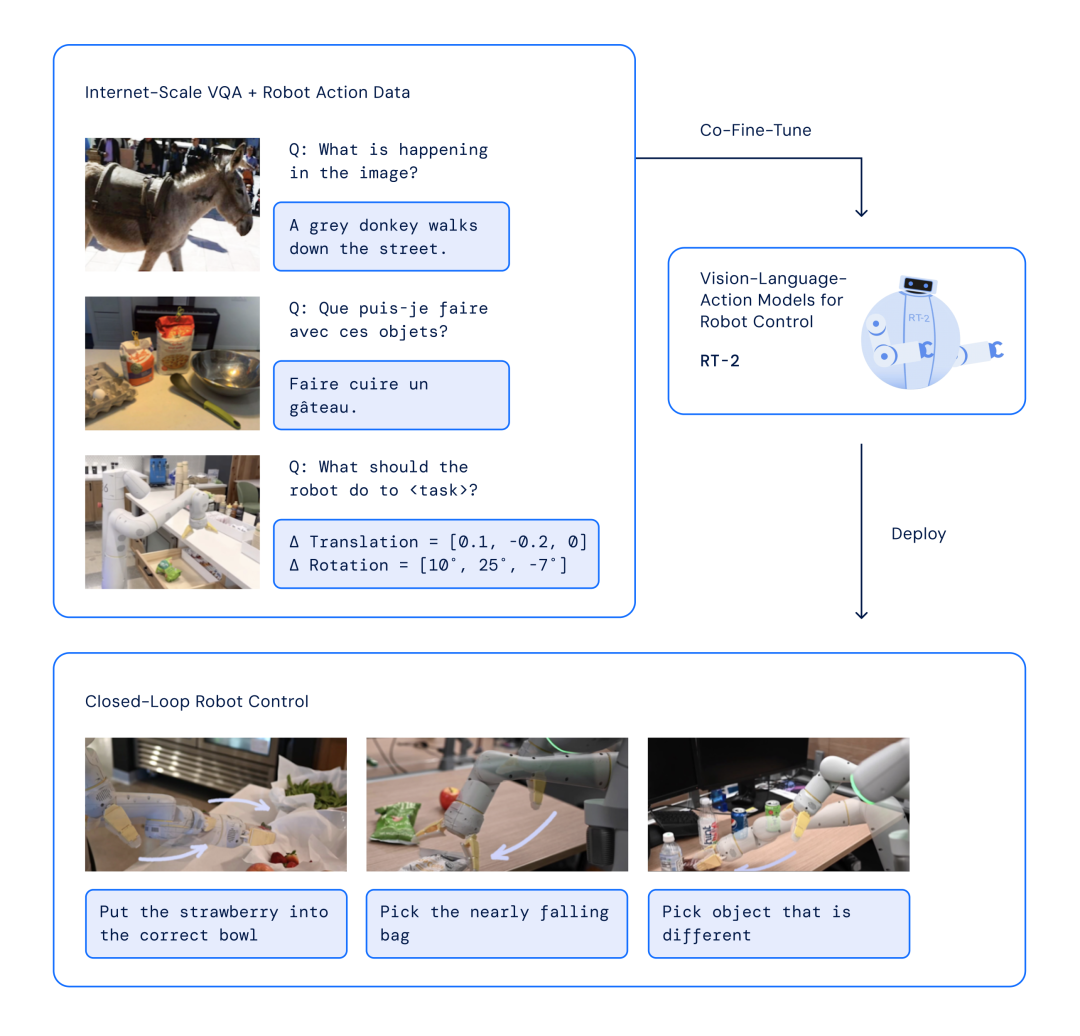
▲RT-2架构和训练:研究人员针对机器人和网络数据共同微调预先训练的VLM模型。生成的模型接收机器人摄像头图像并直接预测机器人要执行的动作。
03. 泛化性能和紧急技能显著更好
研究人员在RT-2模型上进行了一系列定性和定量实验,进行了6000多次机器人试验。
在探索RT-2的新兴功能时,他们首先搜索了需要将web-scale数据的知识与机器人的经验相结合的任务,然后定义三类技能:符号理解、推理和人类识别。
每项任务都需要理解视觉语义概念以及执行机器人控制以操作这些概念的能力。需要诸如“捡起即将从桌子上掉下来的袋子”之类的命令,其中要求机器人对机器人数据中从未见过的物体或场景执行操作任务将知识从基于网络的数据转化为可操作的。

▲机器人数据中不存在的新兴机器人技能示例,需要通过网络预训练进行知识迁移。
在所有类别中,研究人员观察到与之前的基线(例如之前的RT-1模型和Visual Cortex(VC-1)等模型)相比,RT-2的泛化性能提高到3倍以上,这些模型是在大型视觉数据集上进行预训练的。
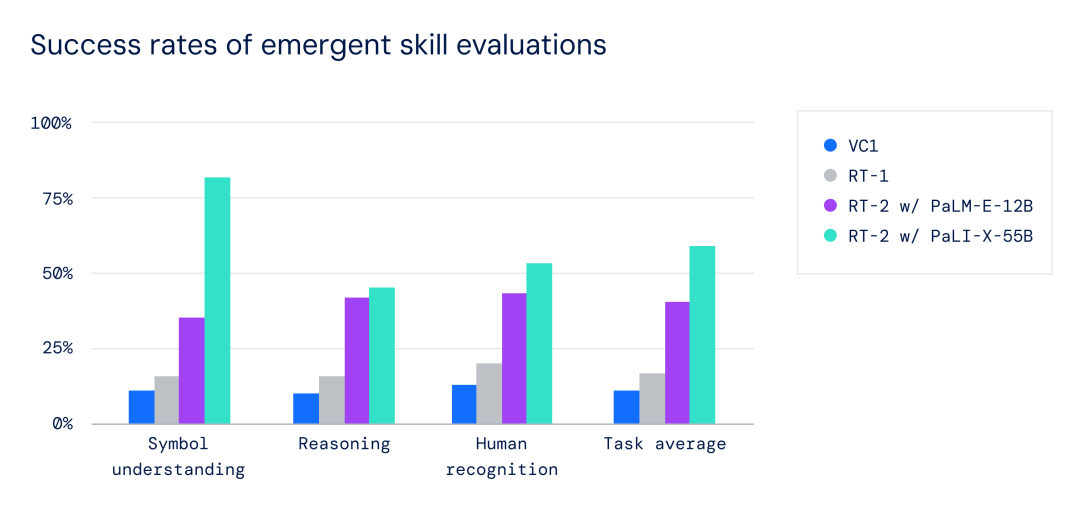
▲紧急技能评估的成功率:RT-2模型优于之前的RT-1和VC-1基线。
研究人员还进行了一系列定量评估,从最初的RT-1任务开始,在机器人数据中提供了示例,然后继续对机器人进行不同程度的以前未见过的物体、背景和环境,要求机器人从VLM预训练中学习泛化能力。

▲机器人以前未见过的环境示例,RT-2可以推广到新的情况。
RT-2保留了机器人数据中看到的原始任务的性能,并提高了机器人在以前未见过的场景上的性能,从RT-1的32%提高到了62%,展示了大规模预训练的巨大优势。
此外,研究人员观察到与仅视觉任务预训练的基线相比有显著改进,例如VC-1和机器人操作的Reusable Representations for Robotic Manipulation(R3M),以及用VLM进行对象识别的算法,例如Manipulation of Open-World Objects(MOO)。
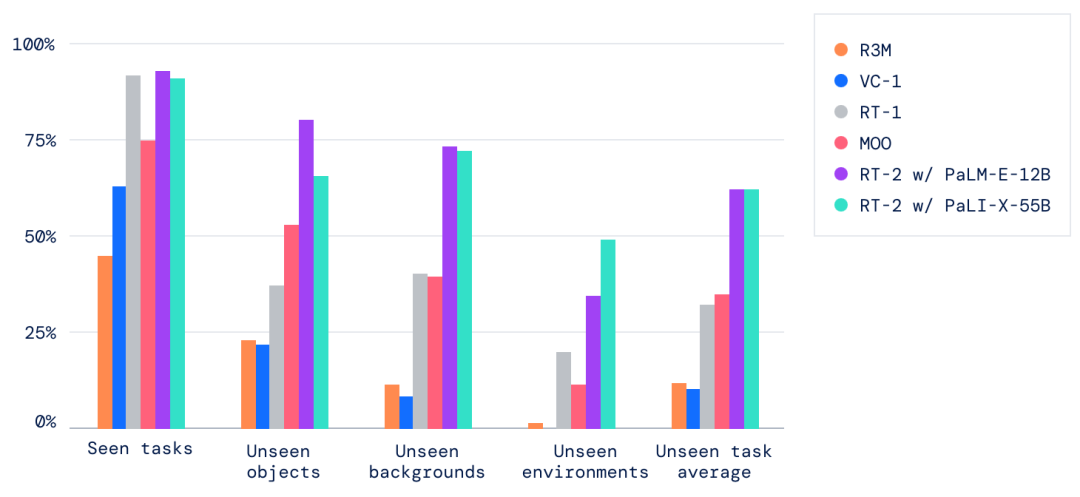
▲RT-2在可见的分布内任务上实现了高性能,并且在分布外未见的任务上优于多个基线。
在机器人任务的开源Language Table套件上评估其模型,研究人员在模拟中实现了90%的成功率,高于之前的基线,包括BC-Z(72%)、RT-1(74%)和LAVA(77%)。
然后研究人员在现实世界中评估相同的模型(因为它是在模拟和真实数据上进行训练的),并展示了其泛化到新对象的能力,如下所示,其中除了蓝色立方体之外,没有任何对象出现在训练中数据集。

▲RT-2在真实机器人Language Table任务中表现良好。除了蓝色立方体之外,训练数据中不存在任何对象。
受大型语言模型中使用思维链提示方法的启发,研究人员探索其模型,将机器人控制与思维链推理相结合,以便能够在单个模型中学习长期规划和简易技能。
特别是,他们对RT-2的变体进行了几百个梯度步骤的微调,以提高其联合使用语言和动作的能力,然后对数据进行了扩充,添加了一个额外的“计划”步骤,首先用自然语言描述机器人即将采取的动作的目的,然后是“动作”和动作标注。
这里,研究人员展示了这种推理和机器人的最终行为的示例:

▲思想链推理可以学习一个独立的模型,该模型既可以规划长期技能序列,又可以预测机器人的动作。
通过这一过程,RT-2可以执行更多复杂的命令,这些命令需要推理完成用户指令所需的中间步骤。得益于其VLM主干,RT-2还可以根据图像和文本命令进行规划,从而实现基于视觉的规划,而当前的计划和行动方法(如SayCan)无法看到现实世界并完全依赖于语言。
04.
结语:机器人制造和编程控制方式
的重大飞跃
多年来,研究人员们一直试图让机器人具有更好的推理能力,以解决如何在现实生活环境中生存的问题。以前,训练机器人需要很长时间。研究人员必须单独制定方向。但借助RT-2等VLA模型的强大功能,机器人可以获取更多信息来推断下一步该做什么。
加州大学伯克利分校机器人学教授肯·戈德堡(Ken Goldberg)说,机器人的灵巧程度仍达不到人类的水平,在一些基本任务上也表现不佳,但谷歌利用AI大型语言模型赋予机器人新的推理和即兴创作技能,这是一个有希望的突破。
谷歌没有立即计划销售RT-2机器人或更广泛地发布它们,但其研究人员相信这些配备新语言的机器最终将不仅仅用于室内魔术,具有内置语言模型的机器人可以放入仓库、用于医药,甚至可以用作家庭助理——折叠衣物、从洗碗机中取出物品、在房子周围收拾东西。
Google DeepMind机器人技术主管文森特·范霍克(Vincent Vanhoucke)认为,这确实开启了在有人所在的环境中使用机器人的大门——在办公室环境中,在家庭环境中,在所有需要完成大量体力任务的地方。
当然,在杂乱无章的物理世界中移动物体,比在受控实验室中移动物体要困难。人类本能地知道该如何清理泼到桌上的饮料,但机器人需要更多的指令才能去做这项看似轻而易举的工作。
鉴于AI大型语言模型经常犯错误或发明无意义的答案,将它们用作机器人的大脑可能会带来新的风险。但戈德堡教授说,这些风险仍然很小。“我们并不是在谈论让这些东西失控,”他说,“在这些实验室环境中,他们只是试图在桌子上推一些物体。”
谷歌方面表示,RT-2配备了大量安全功能。除了每个机器人背面都有一个红色大按钮(按下按钮后机器人会停止在轨道上)之外,该系统还使用传感器来避免撞到人或物体。
RT-2内置的AI软件有自己的保护措施,可以用来防止机器人做出任何有害的事情。例如,谷歌的机器人经过训练后不会拿起装有水的容器,因为如果水溢出,它们的硬件可能会损坏。
谷歌的RT-2机器人并不完美。在实际演示中,它把一罐柠檬味苏打水的味道错猜成“橘子味”。还有一次被问到桌子上有什么水果时,机器人回答成“白色”,而正确答案是香蕉。谷歌发言人解释说,该机器人使用了缓存的答案来回答之前测试者的问题,因为它的Wi-Fi曾短暂中断过。
但瑕不掩瑜。RT-2不仅是对现有VLM模型的简单而有效的修改,而且还展示了构建通用物理机器人的前景,该机器人可以推理、解决问题和解释信息,以在现实世界中执行各种任务。
在大型语言模型研究的启发下,机器人正变得更加智能。
责任编辑:
文章来源://www.profoottalk.com/2023/0801/8466.shtml