酶需要在严格定义的细胞环境下工作,若要在宿主生物体或其生活环境之外被利用,可能无法表达或没有良好的催化活性,这就需要提高其热稳定性、催化活性和底物/辅因子特异性转化。保留甚至改善酶在不同环境中的功能成为一个长期的研究目标。
自 1990 年以来,在合成生物学和代谢工程中,改变代谢酶的辅助因子偏好已被认为是控制代谢途径和最大化目标物质生产的关键策略之一。然而,传统上,此类工作涉及广泛的实验性试错,可能无法保证获得最佳结果。目前还没有构建一个可以筛选许多代谢酶的高通量检测方法。人工智能(一种基于计算机的工具)可以最大限度地减少这种反复试验和错误。
近日,在一项发表于 ACS Synthetic Biology 的研究中,来自大阪大学的研究人员结合人工智能简化了传统上缓慢的酶工程过程。这项工作可能有助于研究人员为特定应用领域,如制药或生物燃料生产,定制目标酶的适应性。这是一个 30 多年来一直难以实现的目标。

(来源:ACS Synthetic Biology)
旨在改变底物和辅因子特异性的酶工程设计
自生命起源以来,具有多种结构和功能的蛋白质通过反复的突变和选择循环而进化。那么,类似于这种自然界中的进化形式,通过人工累积影响其功能的突变也能够获得具有预期功能的蛋白质。
但是,蛋白质的人工进化非常困难,旨在改变底物和辅因子特异性的人工设计尤其具有挑战性。
改变底物和辅因子特异性通常需要引入多个突变,远距离(>10 )突变会显著影响催化功能。尽管在定向进化中反复利用饱和诱变提高了酶的活性和稳定性,必须建立高通量筛选以获得所需的突变体。
机器学习(ML)的加入能够增加选择所需突变体的可能性。此前已有类似的应用案例。一项早期进化工程活动使用 ML 线性模型获得了卤代醇脱卤酶突变体,该突变体可以将体积生产力提高约 4000 倍。这种模型是通过分析来自最初突变残基的蛋白质功能数据来制备的,用于随后的选择轮次。
识别有影响的残基的位置和数量是常规和 ML 辅助蛋白质进化的关键。
为了研究突变位置和辅助因子偏好转换的候选氨基酸,研究人员从京都基因与基因组百科全书(KEGG)数据库中随机收集了 1000 个 NADP+和NAD+依赖型的 MEs 的序列,通过删除重复的序列,获得了 952 个(448 个 NAD+依赖的和 504 个 NADP+依赖的)独特的序列。
最后,286 个序列数据(122 个 NAD+依赖型和 164 个 NADP+依赖型),或数据集的 30%,被用作模型验证的测试集,其余的作为训练集。
该数据集在逻辑回归模型上进行了训练。一个基于训练集的逻辑回归模型被用来区分测试集中的 286 个 ME。
在此,研究人员通过将逻辑回归模型与具有相同折叠结构但辅因子特异性不同的氨基酸序列数据集相结合,来识别参与辅因子特异性的氨基酸残基。
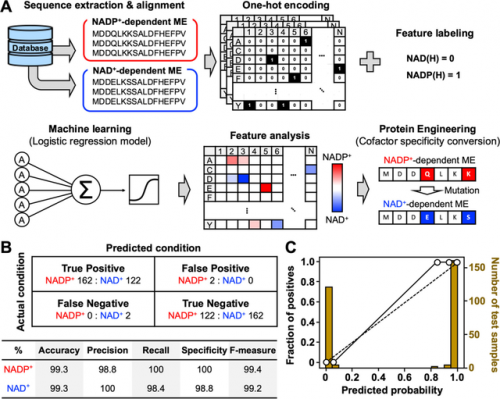
▲图丨(A) 说明用于氧化还原辅因子特异性转换的基于 ML 的酶设计的关键步骤;(B) 混淆矩阵和性能指标;(C) 用于估计预测精度的校准图(来源:ACS Synthetic Biology)
具体来说,假设具有不同底物/辅因子特异性的结构同源酶之间的保守残基是可互换的,并且可能会改变它们的底物/辅因子特异性。利用逻辑回归模型可以准备一个对应于具有复杂特征但没有阐明晶体结构的酶的氨基酸排名表,并指定突变位置,这将允许优先突变设计并有效限制搜索空间。
研究人员还通过将大肠杆菌苹果酸酶(ME)的辅助因子特异性从 NADP+依赖型转换为 NAD+依赖型,验证了这一概念。即通过识别在进化过程中没有改变的氨基酸序列,确定了适应不同物种、不同细胞条件的氨基酸突变。大肠杆菌 K12 菌株(MaeB)是一个合适的验证概念的模型,因为它的三维结构尚未被阐释。研究中构建的模型对 ME 的辅助因子特异性判别准确率超过 99.3%。
ME 广泛存在于微生物、培养细胞、动物和植物胞浆中,尤其在植物组织中活性较高。ME 催化苹果酸氧化脱羧的可逆反应,产生丙酮酸和 CO2,以及伴随 NAD(P)+的还原反应,是苹果酸代谢的关键酶。因此,NAD+和 NADP+依赖型的 ME 都有大量的序列数据。通过获得不同物种的 ME 氨基酸序列,最终获得负责辅助因子特异性的残基。

▲图丨显示氨基酸残基特性与氧化还原辅因子关系分数的对齐热图(来源:ACS Synthetic Biology)
简而言之,该研究使用逻辑回归模型来确定每个位置的 NAD+- 和 NADP+- 依赖型酶背后的氨基酸,按照特征差异最明显的顺序替换氨基酸,由此达成辅助因子特异性的切换。
有趣的是,在开发的 ML 模型选出的几十个单元中引入突变并没有对结构产生任何致命的负面影响。这更加说明了,将 ML 与系统发育分析结合起来用于酶学设计以改变辅助因子特异性是有潜力的。
具有扩展到合成生物学和代谢工程领域的潜力
这项研究的重点在于,使用分类的输入数据和一个简单的多元回归模型,可以高准确度和可读性地预测蛋白质功能。虽然这种方法需要为每个蛋白质建立一个优化的模型,但它使研究人员能够以较高的准确度对酶进行分类和设计。因此,这种方法可以帮助估计控制单个蛋白质功能的残基,并在不改变框架的情况下修改底物和辅助因子特异性。
过去,ML 被用来预测底物特异性,该研究中提出的专注于单个氨基酸残基的辅助因子特异性修饰将进一步扩大 ML 的应用范围。
在讨论中,研究人员这样写道,“尽管我们只使用了带有辅助因子特异性标签的氨基酸序列作为输入,但为每种酶增加更多的参数,包括催化活性和变性中点,将使我们能够根据这些数值来权衡每种酶。这最终将有利于建立一个有影响力的 ML 模型,例如,可以改变底物特异性,同时增加酶的活性。”
研究人员还强调,这项研究重新设计了苹果酸脱氢酶(MaeB)的辅助因子特异性,从 NADP+到 NAD+,没有结构信息和筛选步骤。因此,它代表了一种多功能的方法,具有扩展到合成生物学和代谢工程领域的潜力。
总之,该研究利用从具有相同结构但不同功能的数据集中得出的逻辑回归模型来转换具有未知立体结构的酶的功能,而不造成致命的不稳定。虽然定向进化一般只限于蛋白质的几个突变,但此模型允许引入几十个突变,就像在蛋白质的巨大搜索空间中引导一条路径。由于这种方法是一个使用大量序列信息的统计过程,因此有可能搜索到仅从结构信息中无法发现的热点残基。按贡献率的加法顺序积累的突变并没有破坏蛋白质结构。即使仅从序列数据中也能可靠地改变一个辅助因子的特异性,这是逻辑回归模型的一个优势。



访谈
更多做行业赋能者 HID迎接数字化浪潮新机遇 破解新挑战
今年3月份,全球可信身份解决方案提供商HID发布了最新的《安防行业现状报告》(以下简称“报告”),该报告…
数字化浪潮下,安防厂商如何满足行业客户的定制化需求?
回顾近两年,受疫情因素影响,包括安防在内的诸多行业领域都遭受了来自市场 “不确定性”因素的冲击,市场…
博思高邓绍昌:乘产品创新及客户服务之舟,在市场变革中逆风飞扬
11月24日,由慧聪物联网、慧聪安防网、慧聪电子网主办的2022(第十九届)中国物联网产业大会暨品牌盛会,在深…