目前大多数诊断疾病的AI模型都是在人类标注好的图像基础上进行机器学习训练的,为了使模型以合理的性能预测某种病理,必须在训练期间为该病理提供大量专家标记的训练示例。这种获得某些病理的高质量注释的过程既昂贵又耗时,通常会导致临床工作流程的出现大规模低效的问题。
一个名叫CheXzero的新算法模型诞生了!它可以在现有的医学检查报告中自主“学习”,这些报告是研究人员用自然语言(Natural Language Processing,NLP)撰写的。相关研究成果以题为“Expert-level detection of pathologies from unannotated chest X-ray images via self-supervised learning”发表在Nature Biomedical Engineering(图1)。

图1 研究成果(图源:[1])
研究表明,在涉及医学图像解释的任务中,经过适当训练的机器学习模型通常会超过医学专家的表现。然而,如此高水平的性能通常需要使用专家精心注释的相关数据集来训练模型。研究中展示出模型在无明确注释的胸部X射线图像上自我监督模型执行病理学分类任务,其准确性可与放射科医生相媲美。在胸部X光片的外部验证数据集上,自我监督模型在检测三种病理(共八种)方面优于完全监督模型,并且性能推广到未明确注释模型训练的病理,到多种图像解释任务和来自多个机构的数据集。通过AI模型来理解医学图像这一目的,可以大幅度节省时间和资金成本。
来自哈佛医学院的一组研究人员,利用一份公开可用的数据集,对CheXzero模型进行了训练,该数据集包含超过377000张的胸部X光片和超过 227000份相应的临床报告。研究人员利用分别来自于两个不同机构,以及另一个国家的不相关数据集,对CheXzero的性能表现进行了测试,以检验即使是在报告中包含不同术语的情况下,模型也能够将图像与相应的报告进行匹配。
研究发现:
01
CheXzero无需对任何标记样本进行训练即可对病理进行分类
在没有明确标签的情况下,零样本方法与放射科专家和完全监督方法在训练期间未明确标记的病理学的表现相当(图2)。具体来说,自监督方法比 CheXpert竞赛中表现最好的全监督模型低-0.042点。该模型从原始放射学报告中学习特征,作为监督的自然来源。对于每种病理,生成了一个积极和消极的提示(例如“合并”与“不合并”)。通过比较正面和负面提示的模型输出,自我监督方法计算病理的概率分数,这可用于对其在胸部X射线图像中的存在进行分类。
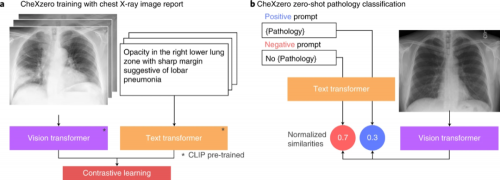
图2 试验过程(图源:[1])
在训练期间不使用显式标签的情况下,自监督模型在CheXpert数据集上优于之前的三种标签高效方法(MoCo-CXR、MedAug和ConVIRT)。MoCo-CXR和MedAug仅使用胸部X射线图像进行自我监督。自监督模型在不使用任何标签或微调的情况下实现了这些结果,从而显示了模型在零样本任务上的能力。
02
CheXzero识别胸腔积液方面水平显著高于放射科医师
该模型的F1评分在胸腔积液方面显著高于放射科医师,在心脏肿大、实变和水肿方面无统计学差异。自我监督模型的 ROC 曲线与放射科医生与测试集基本事实的比较。当ROC曲线高于放射科医师的操作点时,该模型优于放射科医师。
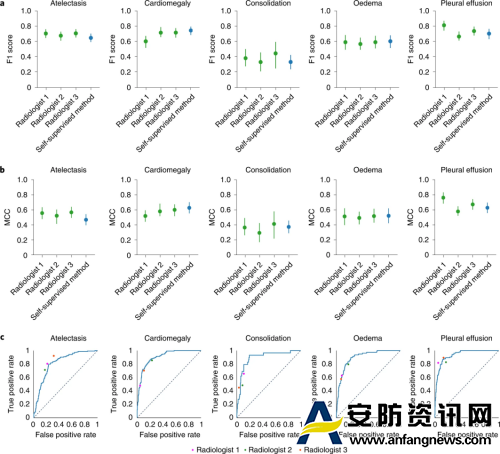
图3 试验过程(图源:[1])
这表明自我监督模型的性能与放射科医生的性能相当,因为在五种CheXpert竞争病理学中,模型的性能与放射科医生在平均MCC(Matthews correlation coefficient)和F1上的性能之间没有统计学上的显著差异。
03
CheXzero拥有在海量数据中泛化到数据集的能力
自我监督方法能够在与训练数据集不同的国家/地区收集的数据集上以高精度预测鉴别诊断和射线照相结果。这种从截然不同的分布中泛化到数据集的能力一直是医疗人工智能部署的主要挑战之一。自监督模型可以更好地泛化,因为它能够利用非结构化文本数据,其中包含可适用于其他数据集的更多样化的射线照相信息。此外,该研究中值得关注的是如果我们使用替代标签而不是PadChest中的原始临床发现。结果表明,自我监督方法可以很好地概括不同的数据分布,而无需在训练期间从PadChest中看到任何明确标记的病状。
综上,新的AI算法模型CheXzero自我监督的方法在胸部X射线分类任务中匹配放射科医生级别的性能,用于模型未明确训练分类的多种病理。研究结果突出了深度学习模型利用大量未标记数据进行广泛的医学图像解释任务的潜力,从而可以减少医疗人员对标记数据集的依赖并减少大规模标记导致的临床工作流程效率低下。
普拉纳夫·拉杰普卡尔(Pranav Rajpurkar)是哈佛医学院布拉瓦特尼克研究所生物医学信息学的助理教授,主导了本研究项目。他说:“我们希望人们能够以‘开箱即用’的方式,将模型应用于他们所关心的其他胸部X光图像数据集和疾病类型。我们是第一个这样做并在该领域有效地证明这一点的人。该模型的代码已向其他研究人员公开,希望它可以应用于CT扫描、MRI 和超声心动图,以帮助检测身体其他部位的更广泛的疾病。需要监督诊断的AI模型可以帮助在专家稀缺的国家和社区增加获得医疗保健的机会。”
德国初创公司Vara的机器学习主管Christian Leibig 表示:“使用报告中更丰富的训练信号非常有意义,Vara正在使用人工智能检测乳腺癌。其能达到AI检测疾病这样的性能水平是一项非常大的成就。”
撰文|乔维钧
排版|文竞择
参考资料:
[1]Tiu E, Talius E, Patel P, et al. Expert-level detection of pathologies from unannotated chest X-ray images via self-supervised learning. Nat Biomed Eng. 2022 Sep 15. doi: 10.1038/s41551-022-00936-9. Epub ahead of print. PMID: 36109605.
[2]https://www.technologyreview.com/2022/09/15/1059541/ai-medical-notes-teach-itself-spot-disease-chest-x-rays/
[3]https://veille-cyber.com/an-ai-used-medical-notes-to-teach-itself/
本文系生物探索原创,欢迎个人转发分享。其他任何媒体、网站如需转载,须在正文前注明来源生物探索。



访谈
更多做行业赋能者 HID迎接数字化浪潮新机遇 破解新挑战
今年3月份,全球可信身份解决方案提供商HID发布了最新的《安防行业现状报告》(以下简称“报告”),该报告…
数字化浪潮下,安防厂商如何满足行业客户的定制化需求?
回顾近两年,受疫情因素影响,包括安防在内的诸多行业领域都遭受了来自市场 “不确定性”因素的冲击,市场…
博思高邓绍昌:乘产品创新及客户服务之舟,在市场变革中逆风飞扬
11月24日,由慧聪物联网、慧聪安防网、慧聪电子网主办的2022(第十九届)中国物联网产业大会暨品牌盛会,在深…